近日,Soul App AI团队(Soul AI Lab)联合西北工业大学ASLP@NPU团队与上海交通大学X-LANCE Lab,正式开源专为多人、多轮对话场景打造的播客语音合成模型SoulX-Podcast。这款模型以丰富的功能特性,为AI语音技术在内容创作与社交场景的落地提供了新可能,成为Soul在“AI+社交”布局中的又一重要成果。
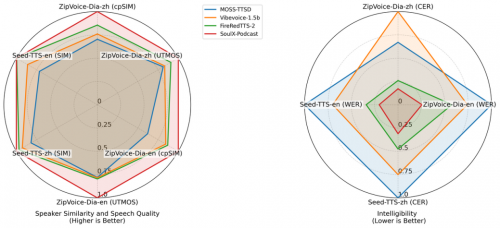
SoulX-Podcast 的核心亮点集中在三大维度,精准解决了当前语音合成领域的多个痛点。在零样本克隆的多轮对话能力上,它不仅能高度还原参考语音的音色与风格,还能根据对话语境灵活调节韵律与节奏,即便面对多轮长时对话或情感丰富的交流,也能保持声音连贯与表达真实,同时支持笑声、清嗓等副语言元素的可控生成,大幅提升合成语音的临场感。
在多语种和跨方言的克隆能力方面,除中英文外,模型还覆盖四川话、河南话、粤语等主流方言,更实现了跨方言音色克隆——仅提供普通话的参考语音,就能生成带方言特征的自然语音,进一步拓宽了使用场景。而在超长播客生成上,SoulX-Podcast可稳定输出超60分钟的多轮语音对话,全程维持音色与风格的一致性,满足长篇内容创作需求。
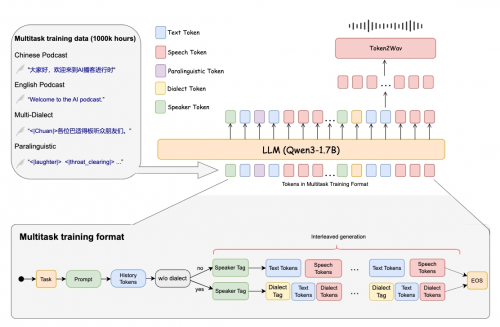
从技术基础来看,SoulX-Podcast采用业界常用的LLM + Flow Matching的语音生成范式,其中LLM部分以Qwen3-1.7B为基座模型,并基于原始文本模型参数进行初始化,以充分继承其语言理解能力,为语义token建模提供坚实支撑;Flow Matching则负责进一步建模声学特征,双模块协同确保了语音合成的精准度与自然度。即便脱离播客场景,该模型在传统单人语音合成与零样本语音克隆任务中同样表现出色,在播客生成任务中,相较于近期相关工作,其在语音可懂度与音色相似度方面均取得了最佳结果。
Soul对AI语音技术的深耕并非偶然,声音作为传递信息与情感的重要媒介,一直是Soul平台构建用户“情感纽带”的关键。在Soul,“语音社交”是极具代表性的标签,用户通过语音实时互动构建新关系。此前,Soul已完成端到端全双工语音通话大模型升级并开启内测,新模型赋予AI自主决策对话节奏的能力,AI可主动打破沉默、适时打断用户、边听边说、时间语义感知、并行发言讨论等,实现更接近生活日常的交互对话和“类真人”的情感陪伴体验;同时,平台推出自研语音生成、识别、对话等大模型,应用于“虚拟伴侣”、群聊派对(多人语音互动场景)等场景。今年9月,Soul的虚拟人孟知时与屿你在群聊派对发起的40分钟对话,在没有任何额外投流、仅依靠虚拟人自身自然流量的情况下,迅速引爆社区,房间互动热度刷新平台纪录,受到广大用户热烈欢迎,这也让团队深刻意识到“虚拟IP+AI语音对话”正在成为虚拟内容生态的重要增长点。
正是基于对行业痛点的洞察与自身技术积累,Soul团队决定开源SoulX-Podcast。此前业界能稳定支持多轮自然对话的开源播客生成模型较少,且在方言支持、副语言表达等方面存在不足,SoulX-Podcast的开源恰好填补这些空白,希望携手AIGC社区探索更多可能。
作为Soul在开源社区的全新尝试,SoulX-Podcast的发布不仅展现了Soul在AI语音技术领域的硬实力,更向全球开发者开放了高质量的技术工具,为携手AIGC社区共同探索AI语音在内容创作、社交表达与虚拟生态中的更多可能提供支撑。
Copyright @ 2001-2013 www.3news.cn All Rights Reserved
中国财经时报网 版权所有