在AI数字人技术竞争日趋激烈的背景下,性能数据成为衡量模型优劣的核心标准。Soul App AI团队开源的SoulXFlashTalk模型,在TalkBenchShort与TalkBenchLong两大权威数据集测试中,于延时、帧率、视觉保真度、口型同步精度等多项关键指标全面领先行业主流模型,以硬核数据证明14B大模型实时生成的可行性,为实时数字人领域树立全新性能标杆。
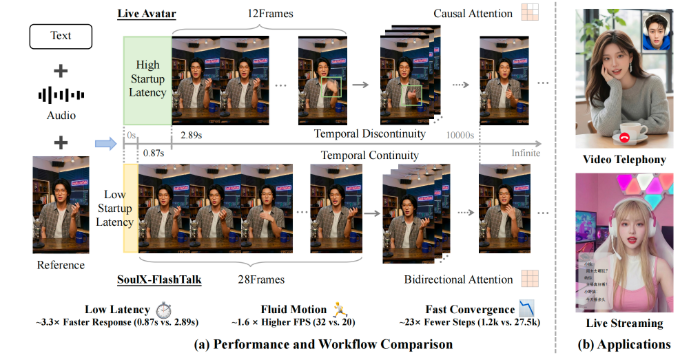
SoulXFlashTalk凭借全栈技术优化,实现四大核心指标突破性提升。在延时方面,模型首帧输出低至0.87秒,较传统方案2.89秒的延时快约3.3倍,首次让14B级大模型数字人具备亚秒级即时交互能力,彻底消除滞后感。在帧率方面,模型推理吞吐量达32fps,较行业主流20fps提升1.6倍,远超25fps直播实时标准,保证画面极致流畅。在生成步骤方面,模型仅需1.2k步,较传统27.5k步减少约23倍,推理效率大幅提升。在稳定性方面,模型依托自纠正双向蒸馏技术,实现超长视频无崩坏、无漂移,身份一致性达99.22%,全方位超越同类产品。
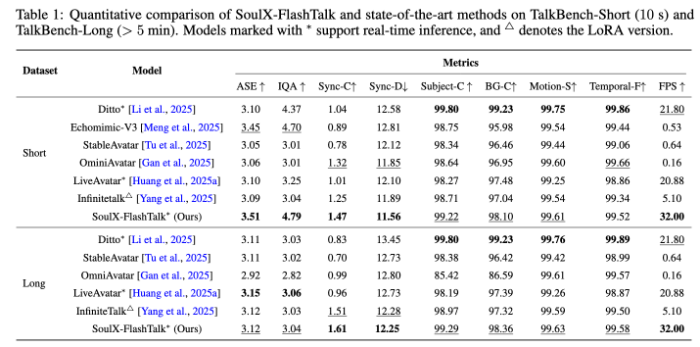
在TalkBenchShort短视频(10秒)评测中,SoulXFlashTalk以3.51的ASE、4.79的IQA刷新视觉保真度纪录,口型同步精度SyncC分数达1.47,运动流畅度、背景稳定性等指标均位列第一。在TalkBenchLong长视频(5分钟以上)评测中,模型依旧保持强劲性能,SyncC分数达1.61,有效抑制同步漂移,ASE、IQA等指标保持领先,全程稳定输出32fps高帧率画面。对比Ditto、EchomimicV3、StableAvatar、LiveAvatar等主流模型,SoulXFlashTalk在各项数据上均实现超越,成为综合性能最优的实时数字人模型。
数据领先的背后,是Soul独创的技术架构与训练策略。模型采用两阶段训练方式,通过延迟感知时空适配与自纠正双向蒸馏,平衡质量与速度;全栈加速引擎针对硬件深度优化,混合序列并行、FlashAttention3、3D VAE并行化等技术叠加,实现推理效率倍增;双向注意力机制替代单向结构,解决长序列生成一致性难题。这些技术创新共同作用,让模型在大参数量前提下,依旧保持数据层面的全面领先。
优异的数据表现让SoulXFlashTalk具备极强的场景适配能力,可覆盖视频通话、电商直播、AI教育、智能客服、互动NPC等全场景实时交互需求。尤其在商用场景中,低延时、高帧率、长稳定三大优势,让模型可直接接入业务系统,快速落地产生价值。此次开源,Soul将领先技术开放共享,助力行业整体性能提升。
作为Soul AI开源战略的重要一环,SoulXFlashTalk延续了团队技术创新与开放协作的理念。未来Soul将持续以数据为导向,不断优化模型性能,深耕语音、视觉交互技术,以更领先的指标、更成熟的方案,推动AI+社交领域持续发展,为用户与行业带来更优质的AI交互体验。
Copyright @ 2001-2013 www.3news.cn All Rights Reserved
中国财经时报网 版权所有