在AI数字人快速发展的当下,延迟高、帧率低、长视频崩坏、动作僵硬等问题一直制约着行业落地。近期,Soul App AI实验室正式开源14B参数量实时数字人生成模型SoulXFlashTalk,以亚秒级延时、32fps高帧率、超长视频稳定生成、全身自然交互四大核心优势,全面重塑实时互动体验,为行业树立全新标杆。Soul始终坚持以技术创新提升产品体验,此次开源不仅让大模型数字人具备商用级实时能力,更为社交、直播、教育、客服等领域提供高质量解决方案。
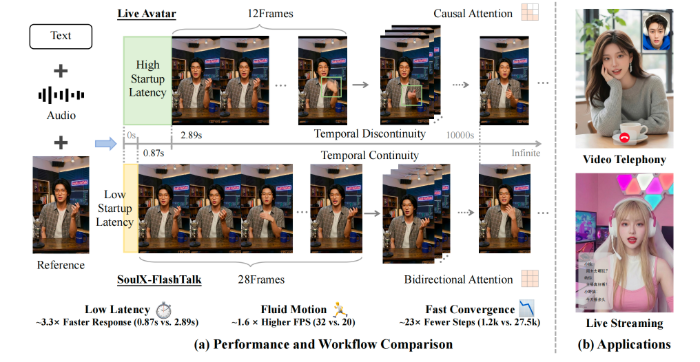
SoulXFlashTalk最核心的突破是实现真正意义上的实时交互。在实时视频场景中,延迟直接决定用户体验,传统大模型数字人普遍存在明显滞后,难以满足自然对话需求。而SoulXFlashTalk通过全栈加速引擎深度优化,将首帧输出延时压缩至0.87s,达到亚秒级响应水平,让140亿参数大模型实现接近零延迟的即时反馈,彻底告别卡顿与滞后感。无论是视频通话中的即时对答、直播间弹幕秒级互动,还是智能客服的实时响应,都能实现流畅自然的深度交流,大幅提升用户沉浸感与真实感。
在流畅度方面,SoulXFlashTalk同样实现行业领先。尽管搭载14B参数量超大DiT模型,模型推理吞吐量仍稳定达到32fps,远超直播所需的25fps实时标准,保证画面全程丝滑顺畅。这一成果证明,超大参数量模型经过深度加速优化后,依然可以兼顾强大生成能力与高效运行效率,打破了行业“大模型必慢”的固有认知。在长视频生成能力上,模型凭借自纠正双向蒸馏技术与多步回溯自纠正机制,实时修正生成误差,保留双向注意力机制,避免身份漂移、面部不一致、画质下降等问题,即使长时间连续生成也能保持清晰稳定,完美适配全天候直播、长视频创作等场景。
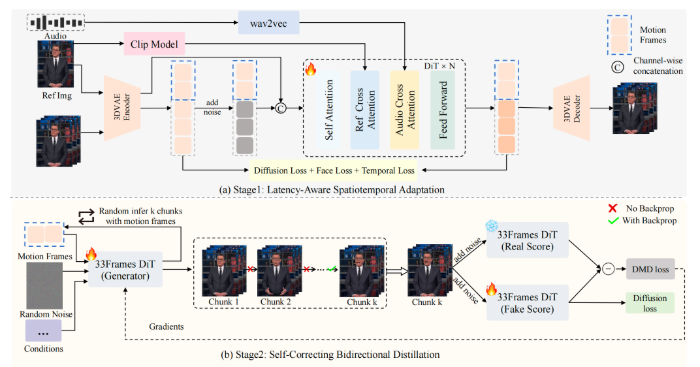
训练流程示意图
SoulXFlashTalk还实现了从面部驱动到全身动态的跨越,不再局限于简单口型对齐,而是支持音频驱动的全身肢体动作生成,动作自然舒展,符合人体运动逻辑。同时,模型在手部细节还原上表现突出,能够精准生成结构清晰、纹理细腻的手部动作,消除畸形与模糊问题,整体交互更贴近真人表现。在专业评测中,模型在视觉保真度、口型同步精度、生成稳定性等维度均取得高分,长短视频表现均优于行业主流模型。
凭借优异性能,SoulXFlashTalk可广泛落地多元场景,在电商直播中实现全天候稳定运行,降低运营成本;在短视频制作中提升生产效率与内容质量;在AI教育、互动娱乐、智能客服等领域提供高质量交互方案。Soul将持续投入AI研发,不断优化实时交互能力,以开源模式推动技术共享,为用户打造更智能、更沉浸、更有温度的AI社交体验。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
Copyright @ 2001-2013 www.3news.cn All Rights Reserved
中国财经时报网 版权所有